
Trading Compute for Memory: Using Activation Recomputation with GPT2

One of the most obvious patterns that we can notice when running training on transformers is that activations take up the most memory:
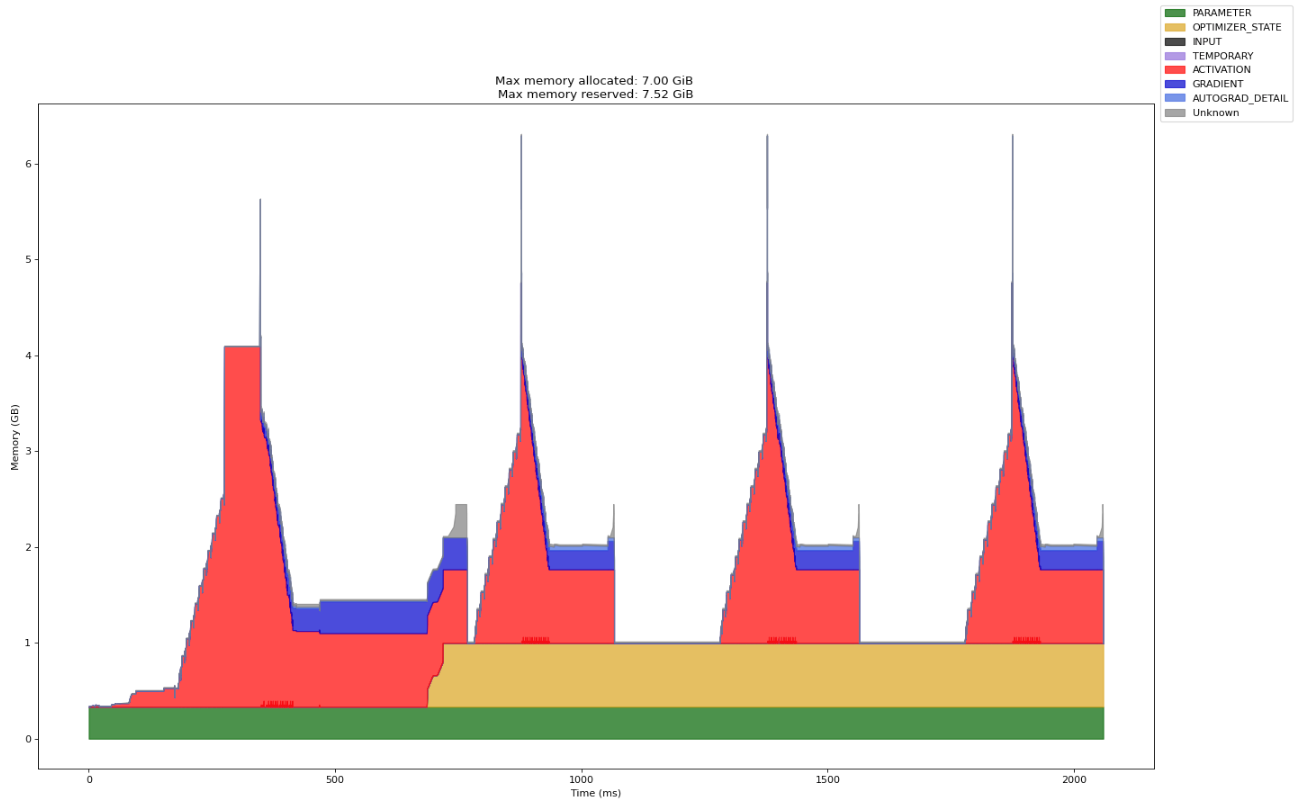
In my last post, I talked about training a GPT2 model and did some basic memory profiling with the PyTorch profiler and memory snapshot tool. In this one, I’m going to implement activation recomputation, one of the most common methods to reduce activation memory in transformer training.
Why does activation memory grow?
During our forward pass, we compute activations for every layer and store them so that we can calculate the corresponding gradients during backpropagation. But the problem is that activation memory grows linearly with batch size and quadratically with sequence length:
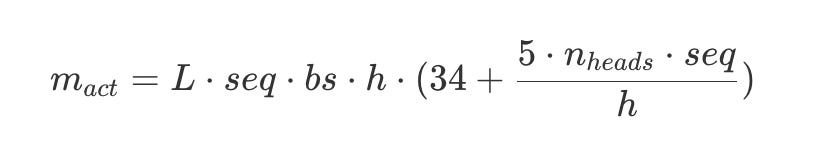
The reasons are pretty intuitive. When you increase batch size, you are simply processing more independent sequences in parallel before backpropagation. So if you double the batch size, you have to store double the activations until backprop is run. And when you double sequence length, you quadruple the attention calculation. This is because the attention mechanism computes pairwise interactions between every token in the sequence. Each token attends to every other token, creating an N×N attention matrix. So if we go from N to 2N, then instead of N2 computations, we would have to do (2N)×(2N) = 4N2 computations:
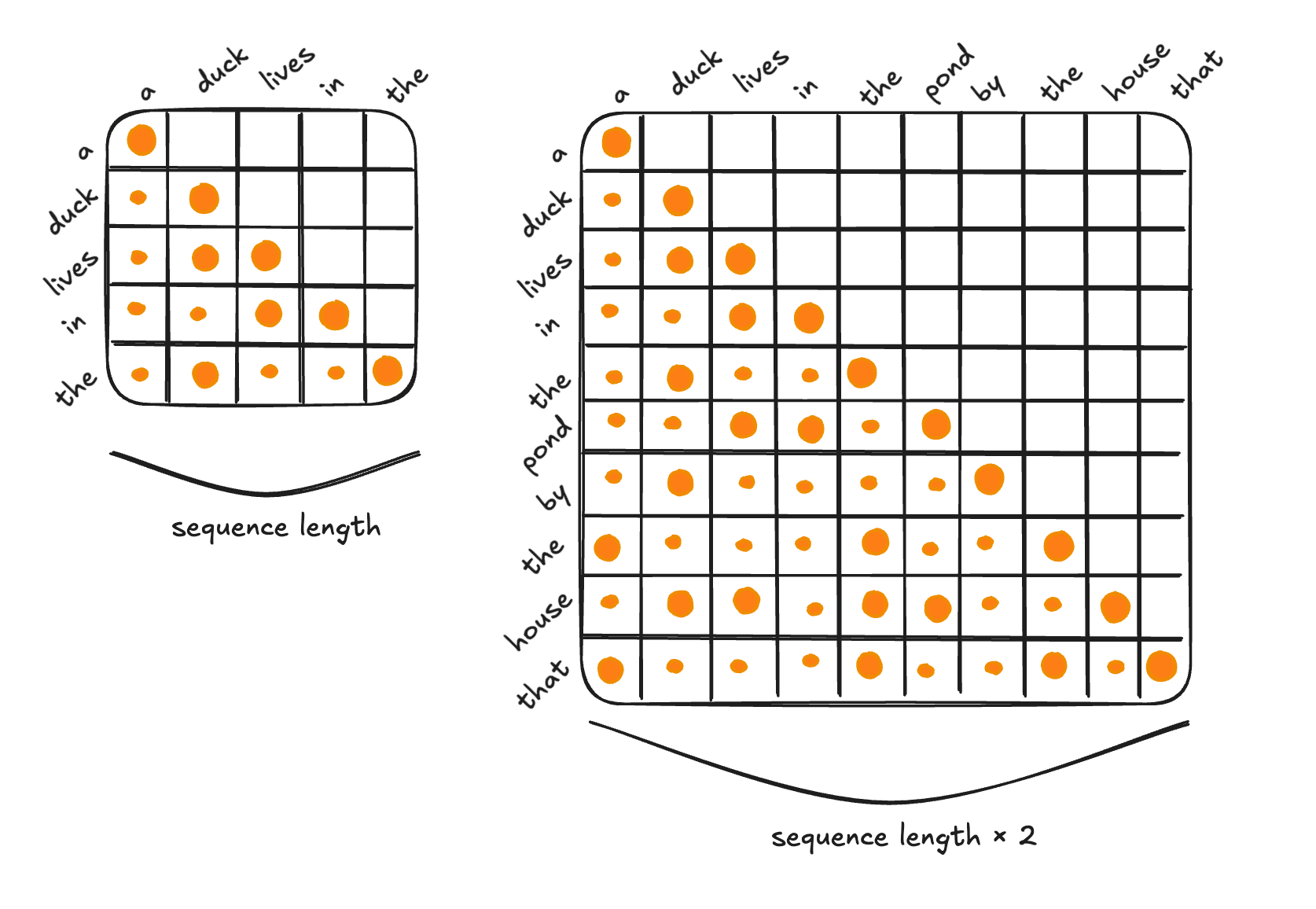
Do we need to cache the activations from the forward pass? It turns out that we do not!
How to get training from not running at all, to running slower
Activation recomputation, in a nutshell, is a memory optimization strategy that involves dropping activations during the forward pass instead of persisting them, and then recomputing them during the backward pass. So you calculate each layer’s output, pass it to the next layer, and then drop it from memory, rather than holding onto those values until backprop. This prevents the activations from building up:
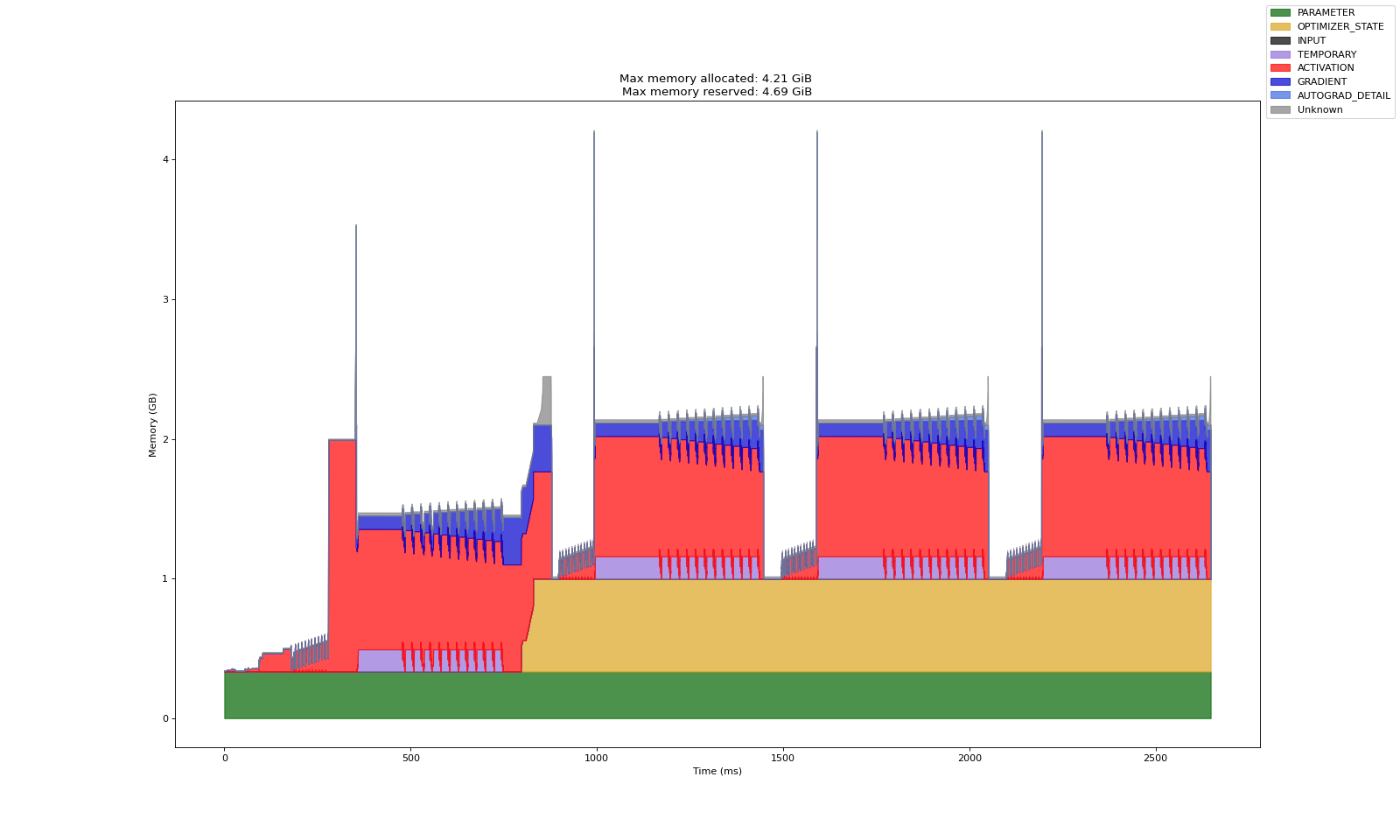
I recomputed activations for the transformer blocks but left the rest of the model (embeddings, unembedding) as is. Notice that the max allocated memory has decreased about 40%, from 7 GB to about 4.2 GB. On average, it takes a batch ~501 ms to run without activation recomputation, and ~598 ms with, which is a 17% increase in training time. Not too shabby of a tradeoff considering we halved the max memory!
With activation recomputation of the transformer blocks, I was able to get the embedding size of my GPT2 model from 512 to 768. Running it the same as last time (prompt is “Tell me a story!”), with 16 sequences per batch and for one epoch on TinyStories, here’s what I get:
That he I the Grand. I the Grand like the Grand. But I his I going not I each I animals the Grand but I trees she I po grains her I began to Grand.
While I animals today. She had presents serious the Grand cl Molly snow and we back he looked up
Well, not quite at superintelligence just yet. And training took 32 hours, about twice as long as the 16 hours it took without activation recomputation (and with a smaller embedding size of 512). Final accuracy after one epoch was at 36%, same as before.
We need to speed up training time as well as reduce memory usage even more. I think it’s time to spread this thing across my other three GPUs :)