
Distributed Data Parallelism in JAX

After building a quad-GPU cluster at home, attempting to train GPT-2 despite severe memory constraints, and doing some early memory optimizations, I wanted to take a step back and understand distributed training at a more fundamental level. I switched from PyTorch to JAX, partly because I wanted to see what the hype was all about, but mostly because JAX’s functional programming style and composable transformations make it really easy to understand data flow.1
In this post, I’m gonna walk through the most naive of training optimizations, data parallelism with no sharding (also known as Distributed Data Parallel in PyTorch-speak), where we split training across multiple GPUs in order to increase batch size and speed up training time. After all, why have one when you can have two at twice the price, right?2
 - John Hurt as S.R. Hadden - IMDb")
First things first
I am embarrassed to say that when I started doing ML research, I had a really hard time wrapping my head around all the training-related jargon:
Epochs
Batches
Mini-batches
Training steps
Samples
In hindsight, it feels obvious, but here’s a diagram that explains everything visually in case you agree with me that ML researchers should not be allowed to name things3:

There are a lot of scaling issues that you can run into when training a large language model. You might keep getting OOM errors for any reasonably sized context window. Or you might not be able to store all the intermediate activations to do gradient calculations during backpropagation. Your model could be so big that it doesn’t even fit on a single GPU!
The scaling problem we are going to solve with Distributed Data Parallel (DDP) is really simple. Your model fits in a single GPU’s memory. Your model can train successfully with a single GPU. But maybe your training process takes three days and you want it to finish in less than one. Or maybe your loss curve is really bouncy and you keep eyeing it every so often, praying that it will converge. These problems can be solved simply by increasing the batch size, but if you do, you start to hit the upper limits of single device memory.
This is where DDP shines.
Splitting up data between devices
The idea is pretty simple if you understand how batches get trained (if you don’t, see my colorful diagram above). If the max batch size that one GPU can take is N, then M GPUs can take N * M sized batches, split into N sized mini-batches. The slightly tricky part is remembering that the GPUs need to communicate with each other in order to update each other’s parameters.
Each GPU needs to do the following:
Load its own copy of the model
Run a forward pass on a batch of data
Calculate a loss value
Run a backwards pass to calculate gradients
???
Update the weights with the gradients such that every GPU has the same weights before running the next batch.
At the end of Step 4, every GPU has its own gradients for each parameter of the model. We can’t just update each copy of the model separately, that would defeat the purpose of distributed training. We want to average together the gradients from all the GPUs and then update all copies of the parameters equally.
To do this, we will use an all-reduce collective operation.
All’s well that reduces well
A collective operation in parallel programming is an operation that moves data across distributed devices, sometimes modifying it as they move.4 The collective operation we need is one that will take values from each device, average them, and then return the average to each device, like so:
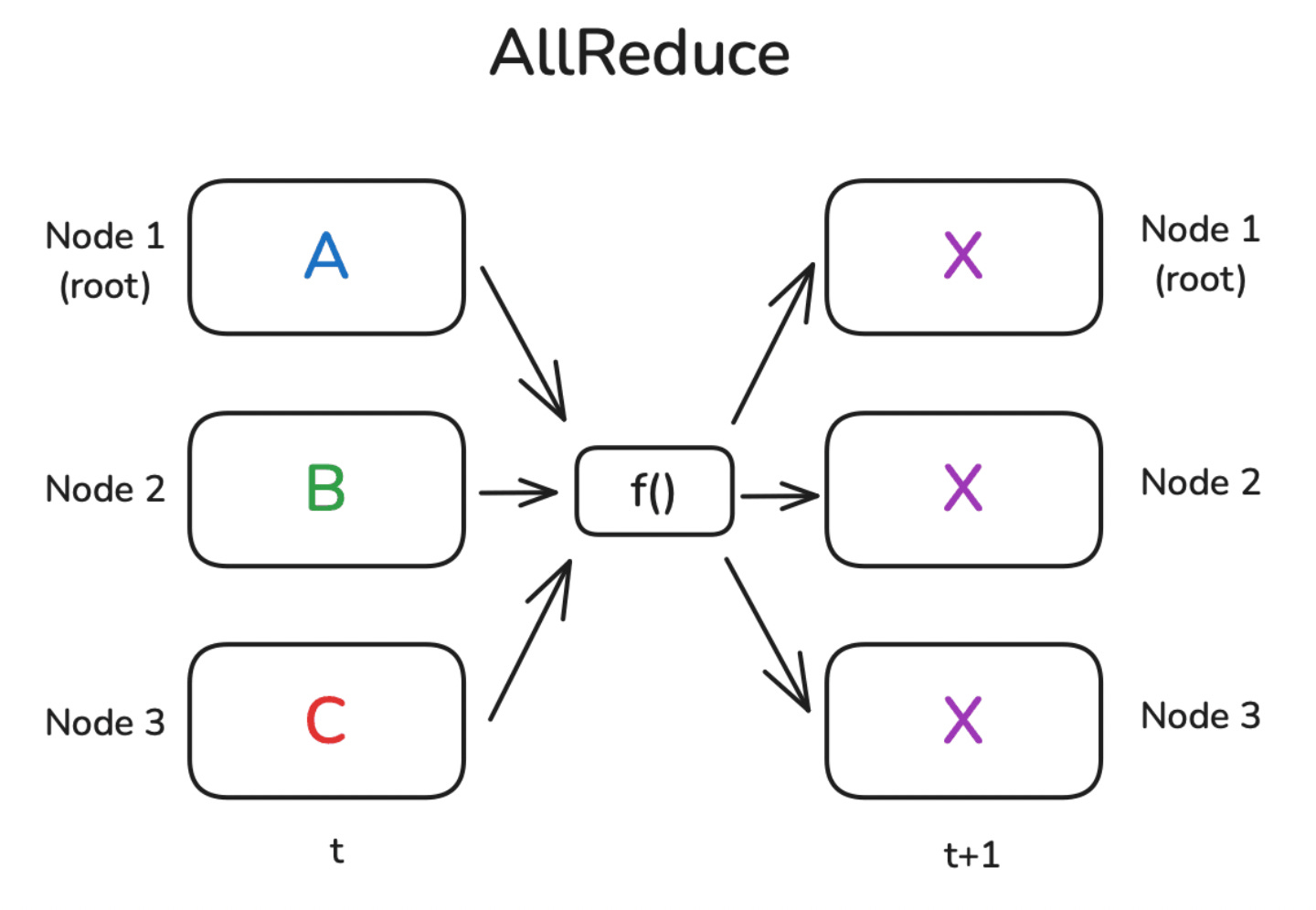
In reality, there’s no imaginary node in the middle that gets data from the other nodes and reduces it. All-reduce is typically implemented using something like Ring AllReduce, where each device transfers a shard of data to another device and adds it, in a ring pattern, until every device has all the data, summed together.5
So after every GPU runs backpropagation and has its own copy of gradients (Step 4), we will do an all-reduce operation that gets the gradients from each device, averages them together, and returns the averages to each device. We can do the same collective operation for the loss calculation so we can get an accurate batch loss value.
Memory profiling
I implemented GPT-2 in JAX and trained it on four NVIDIA 1070 Tis for 16 training steps. It was a success! This was the memory profile during training:

Here’s an annotated version:
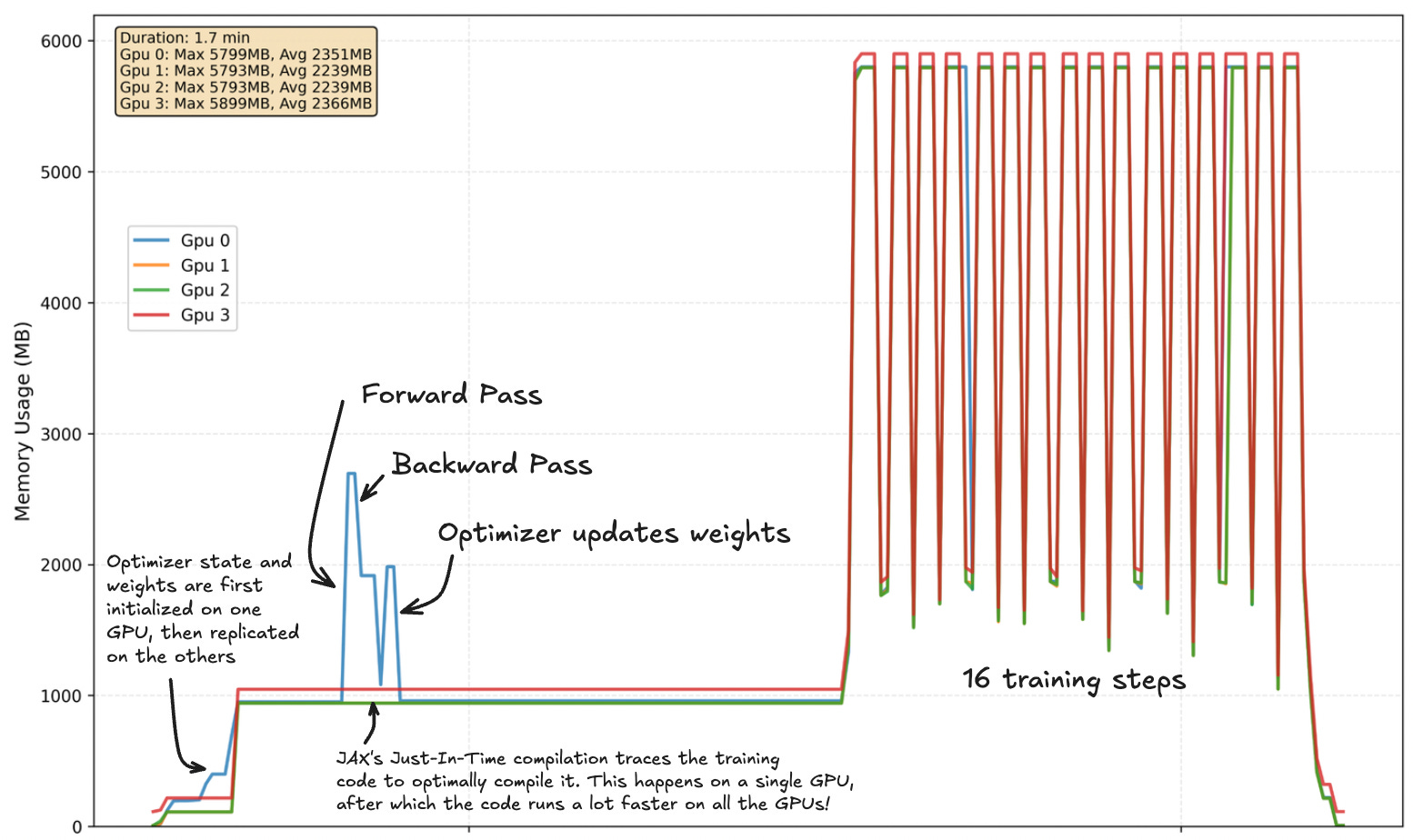
Training GPT-2 using DDP on four GPUs was 56% faster than on a single GPU. Not too shabby! You might be wondering why it wasn’t just four times faster, given that we have four GPUs. Well there’s always a tradeoff! In this case, even though we have more compute units and our batches are bigger, we still have to wait for communication between the GPUs during the all-reduce. No free lunch!
That said, there are a lot of ways to improve training speed, reduce communication bottlenecks, and reduce the memory footprint even further, so stay tuned for future posts.
Overall, this was a really fun project to get a good intuition for how JAX works, as well as how to speed up ML training using multiple accelerators. If you’re interested in trying it out yourself, I’ve put all my code up on Github.
I think PyTorch is fantastic, but using JAX the last couple months has been incredibly refreshing. PyTorch has experienced a “hug of death” of sorts, where it made ML research much easier and approachable than Tensorflow and contemporaries, but it’s just gotten so many updates and additions that it’s not as simple as it used to be. It’s powerful, but I think JAX hides less from you in terms of state management and control flow, especially with distributed training/inference. Tl;dr I switched from PyTorch to JAX because the former is just very big and has a lot going on, while JAX is smaller and simpler, making it really nice for questioning your fundamentals.
Using multiple GPUs has pretty much become the standard in deep learning training ever since it became clear that creating bigger LLMs, trained on more and more data, with higher and higher parameter counts, leads to better performance. There are a lot of questions about how long this can go on for, or if we have already hit the limits. But if you want to train huge models in a reasonable amount of time, you’ll have to use tons of GPUs to get through them.
Before you vehemently disagree with me, consider that the training of a foundational model, i.e. spending millions of dollars over months to train a model, is actually called pretraining. Fine. So pretraining precedes training right? Wrong. It actually precedes “fine-tuning.” So we go from pretraining to fine-tuning. Like I got it eventually, but good lord.
If you are interested in learning more about collective ops, I recommend this crash course from HuggingFace.